こんにちは、SB Intuitions株式会社の大萩雅也、水本智也、高山隼矢です。6月29日、30日に金沢にて開かれた第260回自然言語処理研究発表会 (NL研)にて発表を行いました。
本記事では発表の内容、また発表会の様子について紹介していきます。
目次
発表論文
大規模言語モデルの音声タスクへの応用と分析
著者: 水本 智也, 山崎 天, 李 凌寒, 吉川 克正
本研究では大規模言語モデル (LLM)を音声タスクに応用していくにあたって、LLMが変わることによって、音声タスクでの性能がどのように変わるのかを調べています。
音声を入力としLLMモデルを使って音声タスクを解くベーシックな方法は、以下の図のようにAudio Encoderを用いて音声をエンコードし、その情報をLLMに入力するものです。
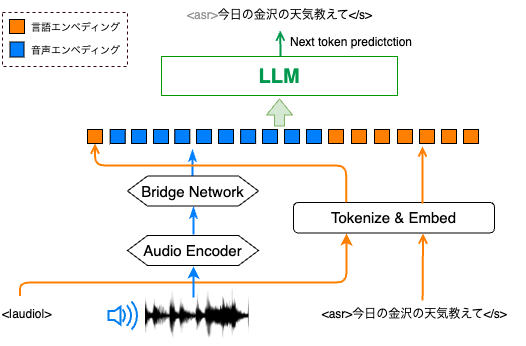
LLMは出力部分を担う重要なモジュールであるにもかかわらず、LLMを変えることによってどの変わるのかは未だ十分な調査がなされてきませんでした。
そこで今回我々は日本語音声タスクにおいて様々な日本語LLMを用いて比較、実験することによってどのようなLLMを用いることが音声タスクの性能向上につながるのかを調べました。今回は音声認識と音声翻訳の2つの音声タスクで評価しました。
結果としては二つの知見が得られています。まず、日本語の音声を入力としてその文字起こしを作成する音声認識タスクにおいてはLLMの性能と音声認識タスクの性能間に強い相関は見られませんでした。

しかしながら、日本語の音声を入力として、それを英訳したテキストを生成する音声翻訳タスクでは言語モデルの翻訳性能と音声翻訳性能の間には一定の相関が見られました*1。

感想
音声を扱う取り組みは著者らも今回が初めてでした。ハイパーパラメーターがちょっと変わるだけで学習できなくなったりや、なかなか下がらなかったロスが急に下がる瞬間があったりと驚きのある実験でした。また機会があればこの辺りも紹介したいと思います。
SB IntuitionsではマルチモーダルなAI開発を目指して、今後も音声を扱えるAIの研究を進めてまいります。今後もご注目ください。
JapanionQA: 大規模言語モデルの意見調査のための日本語データセット
著者: 大萩 雅也, 高山 隼矢, 水本 智也, 吉川 克正
本研究ではLLMがどのような意見を持っているかを調査するためのデータセットを構築&公開しています。
LLMの性能向上により質問応答などの正解のある問題に対しては高い性能が出るようになってきていますが、社会問題などの正解がない問題に対してはLLMがどのような回答を出すのかは未だ明らかになっていません。
欧米においては世論調査をもとにしたOpinionQAなどデータセット、評価手法ともに研究が進んでいますが日本においてはそのどちらにおいても研究が進んでいません。
そこで今回我々は内閣府の世論調査をもとにした日本語意見調査データセットJapanionQAを構築し、それを公開しました。

huggingfaceにデータセット、githubに評価コードをそれぞれ公開しているので是非後続の研究で活用してください。
- データセット:
sbintuitions/japanion_qa · Datasets at Hugging Face
- 評価コード:
GitHub - sbintuitions/japanese_opinion_survey
また、本研究では既存の意見評価手法が日本語においてどの程度頑健性があるのかを検証し、プロンプトへのわずかな摂動がモデルの出力に大きな影響を与えてしまうことを確認しました。詳細については下の発表スライドをご確認ください。
- 発表スライド: JapanionQA.pdf
参加記
第260回NL研の開催地は金沢駅近くのJAISTオフィスでした。初日の朝はあいにくの雨でしたが、駅から近いこともあり雨に濡れることなく会場まで辿り着くことができました。

2日間の開催に収まりきらないのではと思うほど発表件数が多く、たくさんの興味深い発表を聞くことができました。NL研では、発表20分質疑応答10分というように各発表の時間が長めに設定されており、充実した議論が行われているように感じました。オンライン参加者向けにも質問の場が設けられており、活発な議論が行われていました。
発表内容としてはLLMを活用したり、LLMのメカニズムについて分析しているものが多く見られました。しかしながらただLLMを使うだけではなく、それに一工夫加えることで現状のLLMに足りていない部分を補完するといった新たな試みが多く提案されており、いろいろな可能性を感じさせる発表会でした。
初日の夜には懇親会も開かれ、同じ業界にいながら普段はあまり関わることのない方達と良い時間を過ごすことができました。
二日間通して多くの発表がスムーズに行われたのはひとえに運営の方々の素晴らしい進行あってのことだと思います。この場を借りて感謝申し上げます。
面白かった論文
最後に2日間の発表の中で特に興味深かった発表をいくつか紹介していきます
- 国際会議に参加する英語非母語話者の学生を支援する ChatGPTを用いた質疑応答練習システム
- 英語非母語話者が国際会議に参加する際に質疑応答を練習するためのシステムをChatGPTを用いて構築したという発表です。教育応用はよく生成AIの応用先として挙げられますが、この発表ではデモ作成まで行っており完成度と実現性の高さを感じました。私も国際会議での質疑応答はあたふたしてしまうことが多いためぜひこのようなシステムで練習していきたいです。
- 類似性と多様性を同時に考慮する少数事例選択 -市況コメント生成タスクにおける実証分析-
- In-Context Learning(ICL)においてfew-shotをどのように与えるかに関する研究です。本発表ではテスト事例に対する類似性だけではなく、few-shot間の多様性も考慮に入れることによってtest setに対する精度を上げている点が興味深かったです。市況コメント生成タスクにおいて実証実験を行なっていましたが他のタスクに対する応用可能性も色々考えられそうな気がします。
- ポケモン言語学におけるクラスタリング解析
- ポケモンの名前などを手掛かりにして人間が持つ音に対する感覚を解き明かしていこうという「ポケモン言語学」に関する発表です。非常にキャッチーなタイトルでプログラムが発表された時から話題になっていた印象があります。この発表では音象徴ベクトルとモーラ系列の二つを活用したクラスタリングを行いポケモンのタイプごとにどのような音の特徴があるかを分析していました。これからもやれることがすごく多そうな分野なので後続の研究など注目していきたいです。
SB Intuitionsでは今後も様々な研究会で精力的に活動していく予定です。ぜひご注目ください。
*1:音声翻訳タスクは実験できているモデルが少ないので、強く結論づけることはまだできません